
Anyi Rao
Assistant Professor
Human AI | AIGC | Agentic AI
AMC | CSE | EMIA | CMA
MMLab@HKUST
Email: anyirao [at] ust.hk
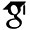



Bio
Anyi Rao is an Assistant Professor at the Hong Kong University of Science and Technology (HKUST), leading the Multimedia Creativity Lab (MMLab@HKUST). He studies human AI, generative AI, agentic AI, computer vision, and computer graphics. His works include ControlNet, AnimateDiff, MovieNet, Virtual Studio, and IC-Light, with a best paper award in computer vision (Marr Prize ICCV best paper award), a best paper award in human-computer interaction (ACM DIS best paper award), and a best ai film award. These works have been widely used in industry, including Amazon, Netflix, Tencent, and more.
He was a Postdoctoral Scholar at Stanford with Maneesh Agrawala. He received the Ph.D. at MMLab, Chinese University of Hong Kong with Dahua Lin and Bolei Zhou. He has research experiences at Meta Reality Lab, Vector Institute, University of Toronto, and University of Hong Kong. He serves as an area chair/TPC of CVPR, ICLR, SIGGRAPH Asia, NeurIPS, UIST, AAAI and co-chair of MMSys, UIST, VINCI, CVM. He is the founding chair of the Hong Kong HKUST AI Film Festival and the Paris ShortFest AI Film Festival.
He is the recipient of the Microsoft Research Asia StarTrack Scholar, Forbes 30 Under 30 Asia, the Rising Star Award at the World Artificial Intelligence Conference, and the Brown Magic Grant.
Actively looking for highly motivated students to join the group. See openings for more details. Please fill out this 2027 form for 2027 intake and send an email if you are interested in.
Full Biography
Anyi Rao is an Assistant Professor in the Division of Arts and Machine Creativity (AMC), the Department of Computer Science and Engineering (CSE), and the Division of Emerging Interdisciplinary Areas (EMIA) at the Academy of Interdisciplinary Studies (AIS) at the Hong Kong University of Science and Technology (HKUST), jointly appointed in the Computational Media and Arts (CMA), HKUST (GZ). He is the Director of Multimedia Creativity Lab (MMLab@HKUST), and the Associate Director of HKUST Media Intelligence Research Center.
He studies human AI, generative AI, agentic AI, computer vision, and computer graphics, focusing on the creation, editing and understanding of art, media and film, aiming to build human-AI collaborative intelligence and unleash human creativity and productivity. His works include ControlNet, AnimateDiff, MovieNet, Virtual Studio, and IC-Light, with a best paper award in computer vision (Marr Prize ICCV best paper award), a best paper award in human computer interaction (ACM DIS best paper award), and a best ai film award. These works have been widely used in industry, including Amazon, Netflix, Tencent, and more.
He was a Postdoctoral Scholar at Stanford with Maneesh Agrawala. He received the Ph.D. at MMLab, Chinese University of Hong Kong with Dahua Lin and Bolei Zhou. He has research experiences at Meta Reality Lab, Vector Institute, University of Toronto, and University of Hong Kong. He serves as an area chair/TPC of CVPR, ICLR, SIGGRAPH Asia, NeurIPS, UIST, AAAI and co-chair of MMSys, UIST, VINCI, CVM. He is the founding chair of the Hong Kong HKUST AI Film Festival and the Paris ShortFest AI Film Festival. He organized the SIGGRAPH/CVPR/ICCV Creative Visual Content Workshop and the SIGGRAPH Generative Models Course.
He has been selected as the Microsoft Research Asia StarTrack Scholar 2026, been featured in the Forbes 30 Under 30 Asia 2025 List, won the Rising Star Award at the World Artificial Intelligence Conference 2024, and hosted the Brown Media Innovation Research Fund and the Amazon Video Research Fund, etc. He gave keynote at the Beijing Film Festival, the Golden Rooster Film Festival, the Shanghai Television Magnolia Festival, was featured by Shanghai TV Financial Channel and Hong Kong Cable Television.
News
More
Selected Publication [Full List]
| MagicPrompt: Ultra-Lightweight Prompt Tuning for Video Generation |
| FlexComposer: Unified Video Compositing from Images to Dynamic Footage with Flexible Trajectory Control |

| UniVidX: A Unified Multimodal Framework for Versatile Video |

| Composing Concepts from Images and Videos via Concept-prompt Binding |

| DataSway: Vivifying Metaphoric Visualization with Animation Clip Generation and Coordination |
| Collaposer: Transforming Photo Collections into Visual Assets for Storytelling with Collages |

| CineVision: An Interactive Pre-visualization Storyboard System for Director–Cinematographer Collaboration |

| IC-Light: Scaling In-the-Wild Training for Diffusion-based Illumination Harmonization and Editing by Imposing Consistent Light Transport |

| ScriptViz: A Visualization Tool to Aid Scriptwriting based on a Large Movie Database |
| AnimateDiff: Animate Your Personalized Text-to-Image Diffusion Models without Specific Tuning |

| ControlNet: Adding Conditional Control to Text-to-Image Diffusion Models |

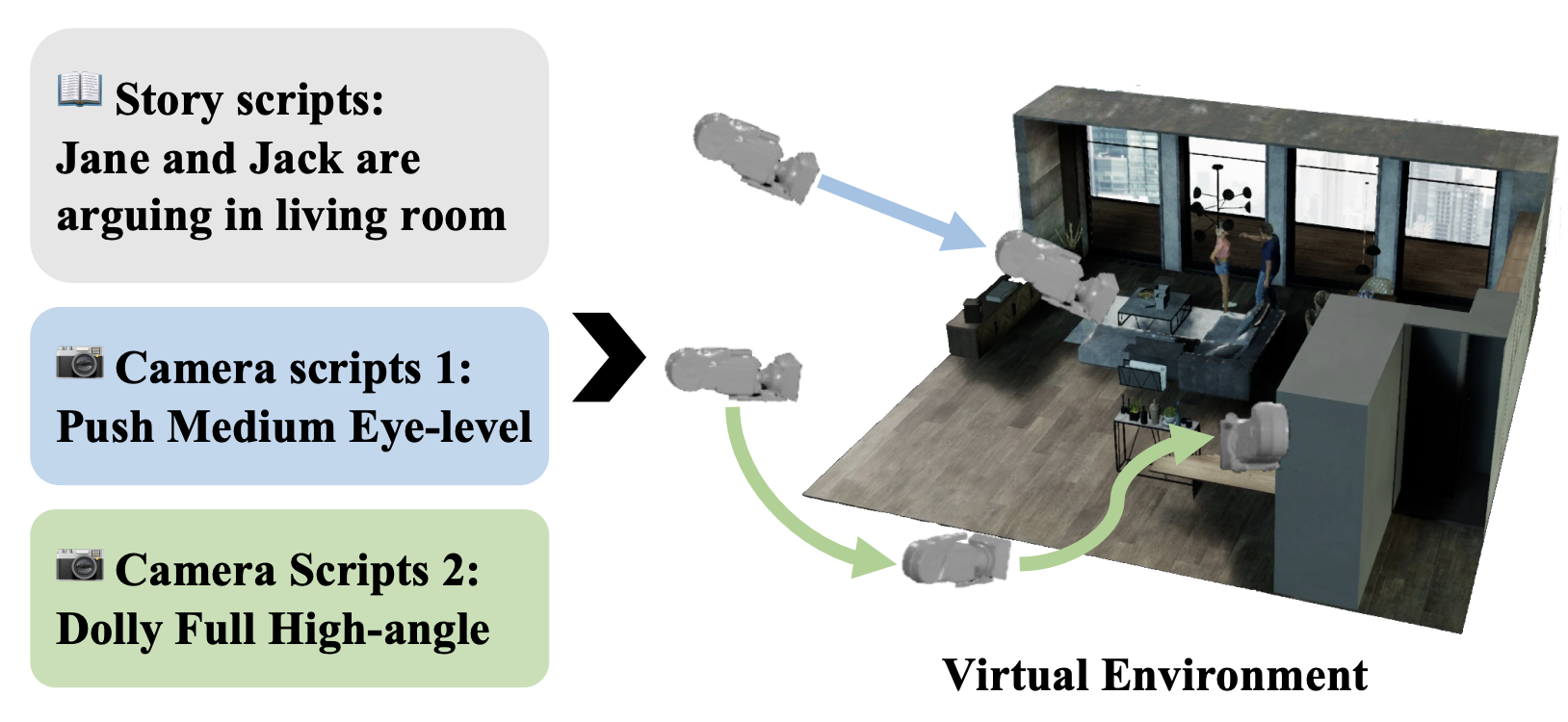
| Dynamic Storyboard Generation in an Engine-based Virtual Environments for Video Production |
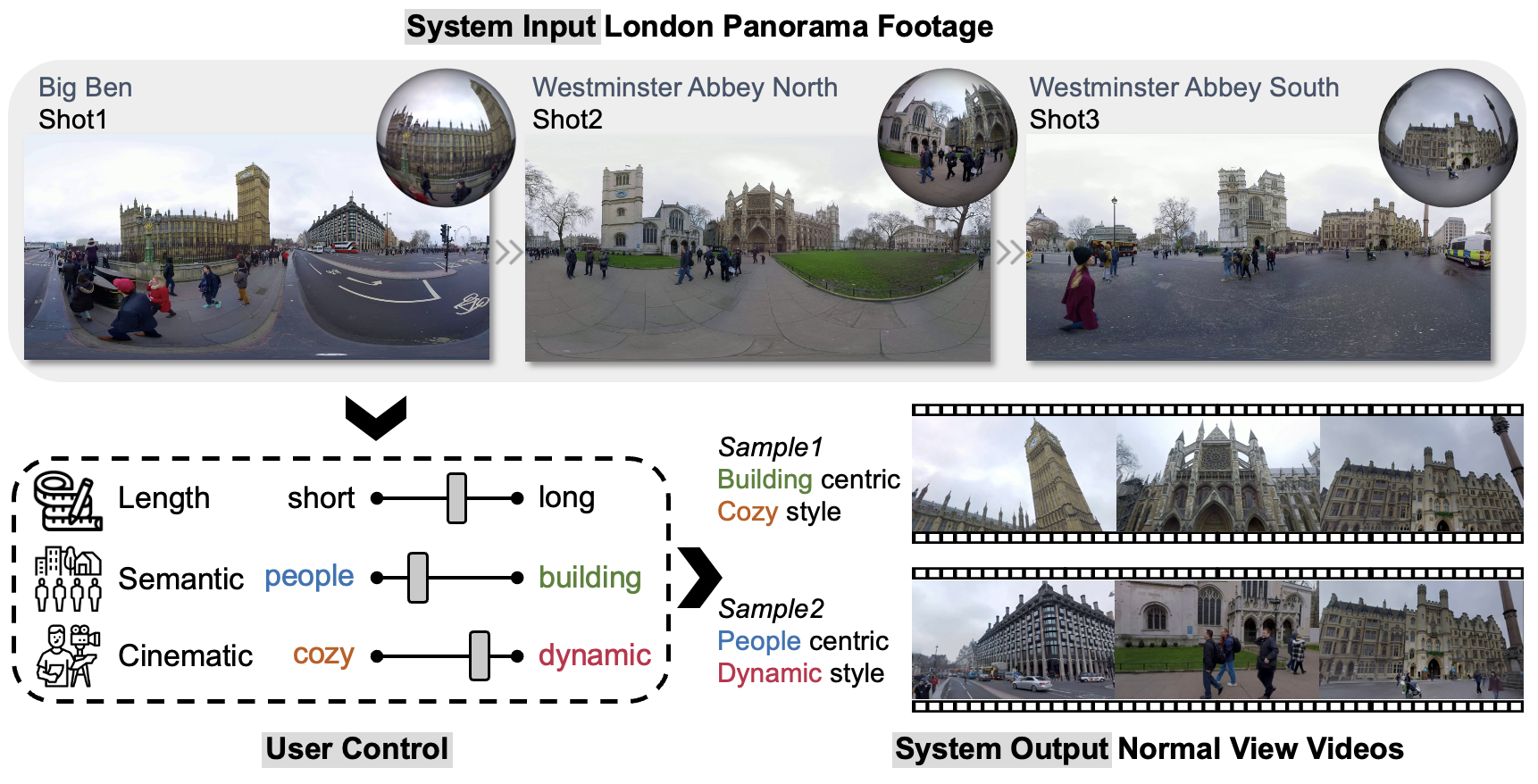
| Shoot360: Normal View Video Creation from City Panorama Footage |
| A Coarse-to-Fine Framework for Automatic Video Unscreen |

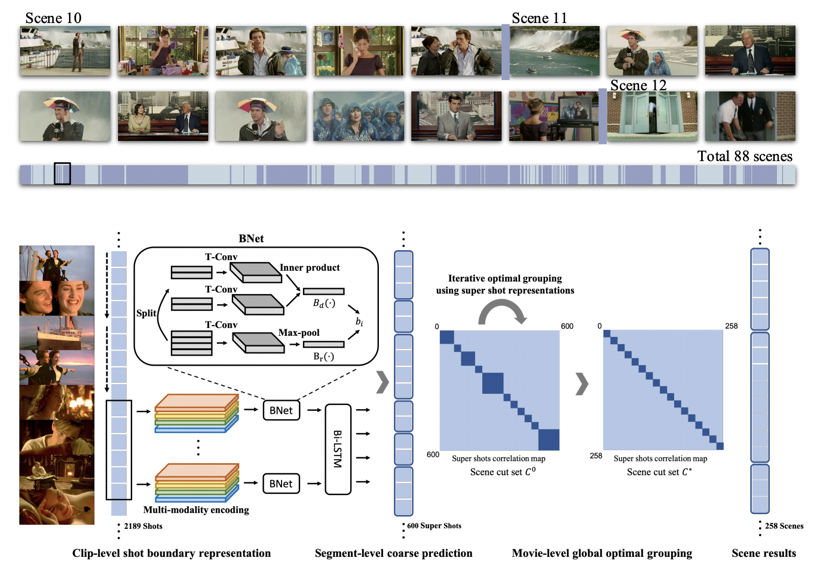
| A Local-to-Global Approach to Multi-modal Movie Scene Segmentation |
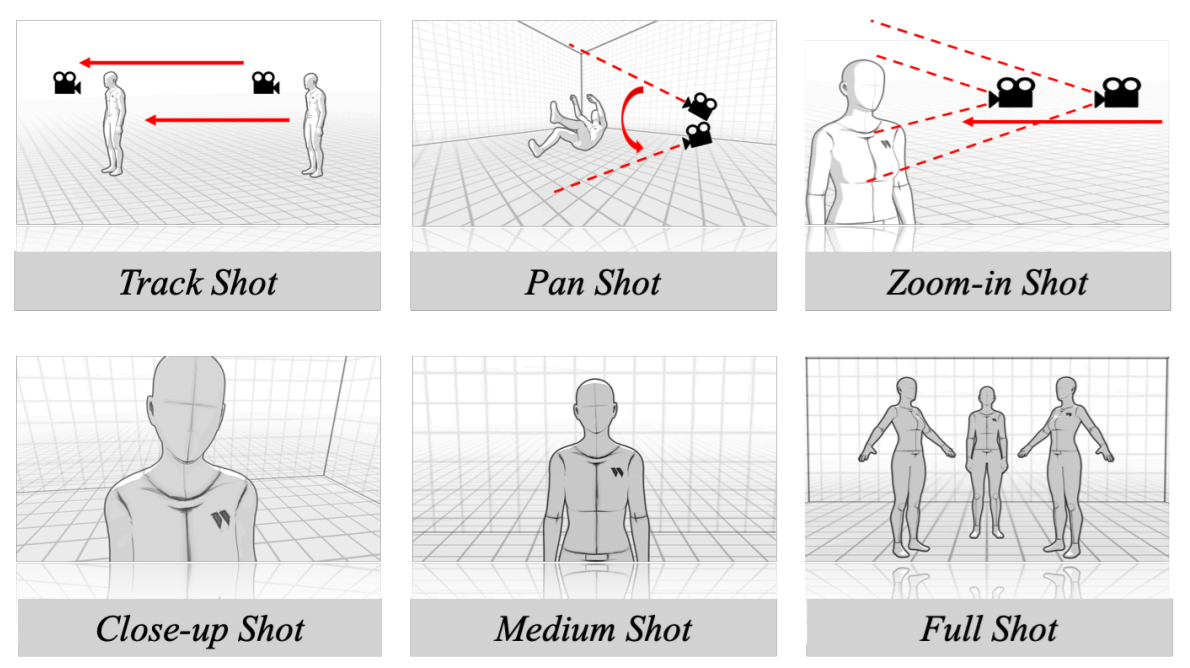
| A Unified Framework for Shot Type Classification Based on Subject Centric Lens |
| MovieNet: A Holistic Dataset for Movie Understanding |

Selected Awards and Grants
| 2026 | |
| 2025 | |
| 2025 | |
| 2025 | |
| 2025 | |
| 2024 | |
| 2024 | |
| 2024 | |
| 2023 | |
| 2023 | |
| 2023 |
More
| 2025 | |
| 2024 | |
| 2023 | |
| 2022 | |
| 2021 | |
| 2021 | |
| 2020 | |
| 2018 | |
| 2017 | |
| 2017 | |
| 2015 | |
| 2013 | |
| 2015 | |
| 2016 | |
| 2015 | |
| 2016 | |
| 2017 | |
| 2016 | |
| 2017 | |
| 2016 | |
| 2016 | |
| 2014 |
{kind=link}
Talks
|
|
|
|
|
|
|
|
|
Press Coverage
Professional Activities
Art Experiences
Research Experiences
Teaching Experiences
Patents